论文:https://www.irisa.fr/lagadic/pdf/2006_ieee_ram_chaumette.pdf
Intro
视觉伺服: 把计算机视觉得到的信息放进控制回路里,用来控制机器人运动。相机可以装在机械臂末端或移动机器人上,也可以固定在环境里;但这篇教程主要聚焦在 eye-in-hand 场景,也就是相机跟着机器人一起运动。
文章的关注点
作者强调,视觉伺服横跨图像处理、计算机视觉和控制理论,但这篇 Part I 不会把这些全展开,而是主要讲:
- 控制问题怎么建模
- 与视觉伺服特别相关的几何问题
同时它不重点讨论特征跟踪和三维位姿估计,因为那两块本身就值得单独讲。
The Basic Components of Visual Servoing
1. 先定义视觉伺服要最小化的误差
论文把误差写成
$$ e(t)=s(m(t),a)-s^* $$
这里:
- $ m(t) $ 是图像测量量,比如特征点坐标、目标质心等;
- $ s(m(t),a) $ 是从这些测量量里提取出来的视觉特征;
- $ a $ 表示一些额外已知信息,比如粗略内参、物体模型;
- $ s^* $ 是目标特征。
也就是说,这一节先告诉你:视觉伺服的目标,就是让当前视觉特征逼近期望视觉特征。
2. 说明本文当前研究的场景假设
这一节限定了 Part I 讨论的是:
- 目标位姿固定;
- 目标本身不动;
- 特征变化只由相机运动引起;
- 控制对象是一个 6 自由度相机。
这个设定是为了先讲最经典、最基础的视觉伺服模型。
3. 给出特征变化和相机速度之间的关系
论文引入了
$$ \dot s = L_s v_c $$
其中 $ v_c $ 是相机空间速度,$ L_s $ 是 interaction matrix(交互矩阵),也常叫 feature Jacobian。
接着因为误差 $ e $ 就是由 $ s $ 构成(对误差公式对时间求导时$ \dot e(t)=\dot s(t)-\dot s^*=\dot s(t) $,所以
$$
L_e = L_s
$$
),所以有
$$ \dot e = L_e v_c $$
这一步非常关键,因为它把“图像/视觉特征怎么变”直接和“机器人该怎么动”连接起来了。
4. 推出最基本的控制律
如果希望误差按指数形式衰减:
$$ \dot e=-\lambda e $$
那么就能得到最基本的速度控制律:
$$ v_c=-\lambda L_e^+ e $$
如果 $ k=6 $ 且 $ L_e $ 可逆,还可以写成
$$ v_c=-\lambda L_e^{-1}e $$
但论文马上强调:现实里 $ L_e $ 或 $ L_e^+ $ 通常不可能精确已知,所以实际控制里常常用它们的估计或近似:
$$ v_c=-\lambda \hat L_e^+ e $$
这就是大多数视觉伺服控制器的基本形式。
Classical Image-Based Visual Servo
- IBVS 直接用图像特征做控制
这一节一开始说,传统 IBVS 直接把图像平面上的点特征坐标当作视觉特征 (s)。常见做法是取若干特征点的图像坐标;图像测量 (m) 通常是像素坐标,而参数 (a) 主要就是相机内参,用来把像素坐标变成归一化图像坐标。也就是说,IBVS 的核心思想是:不先恢复完整三维位姿,而是直接让图像里的特征点走到目标位置。
- 推导交互矩阵
作者接着以单个空间点为例推导交互矩阵。对空间点 $ X=(X,Y,Z) $,其图像坐标记为 $ x=(x,y) $,并取
$$ s=x=(x,y). $$
通过对投影关系求导,并把三维点速度和相机空间速度联系起来,得到
$$ \dot x = L_x v_c, $$
其中 $ L_x $ 是单点的 interaction matrix(交互矩阵/图像雅可比)。这一节的关键含义是:
- 图像特征变化可以线性写成相机速度的函数;
- 但这个矩阵里显式含有深度** **$ Z $;
- 同时图像特征计算还依赖相机内参。
所以,IBVS 虽然是“基于图像”的方法,但并不是完全不需要几何信息;至少要知道或近似知道深度和内参。
单个点特征的交互矩阵(图像雅可比矩阵)推导
1. 问题描述
考虑相机观察一个静态的三维点。设该点在相机坐标系下的坐标为:
$$ \mathbf{P} = \begin{bmatrix} X \\ Y \\ Z \end{bmatrix} $$
其对应的图像点(归一化平面坐标)为:
$$ \mathbf{x} = \begin{bmatrix} x \\ y \end{bmatrix} = \begin{bmatrix} \frac{X}{Z} \\ \frac{Y}{Z} \end{bmatrix} $$
其中,$ Z > 0 $ 是点的深度。
在视觉伺服中,我们通常选取图像点的坐标作为视觉特征,即:
$$ \mathbf{s} = \mathbf{x} = \begin{bmatrix} x \\ y \end{bmatrix} $$
目标是建立图像特征变化率 $ \dot{\mathbf{s}} = [\dot{x}, \dot{y}]^\top $ 与相机运动速度 $ \mathbf{v}_c = [v_x, v_y, v_z, \omega_x, \omega_y, \omega_z]^\top $ 之间的线性关系:
$$ \dot{\mathbf{s}} = \mathbf{L}_s \mathbf{v}_c $$
其中,$ \mathbf{L}_s $ 即为交互矩阵(Interaction Matrix),也称为图像雅可比矩阵(Image Jacobian)。
2. 对投影方程求导
由 $ x = \dfrac{X}{Z} $, $ y = \dfrac{Y}{Z} $,对时间求导,利用商的求导法则:
$$ \dot{x} = \frac{\dot{X}Z - X\dot{Z}}{Z^2} = \frac{\dot{X} - x\dot{Z}}{Z} \tag{1} $$
$$ \dot{y} = \frac{\dot{Y}Z - Y\dot{Z}}{Z^2} = \frac{\dot{Y} - y\dot{Z}}{Z} \tag{2} $$
注意,这里 $ \dot{X}, \dot{Y}, \dot{Z} $ 是点 $ \mathbf{P} $ 在相机坐标系下的速度分量。由于我们假设点是静止的,而相机在运动,因此 $ \dot{X}, \dot{Y}, \dot{Z} $ 实际上是由相机运动引起的点在相机坐标系中的相对速度。
3. 将点的速度表示为相机速度的函数
对于一个相对于相机以角速度 $ \boldsymbol{\omega} = [\omega_x, \omega_y, \omega_z]^\top $ 和平移速度 $ \mathbf{v} = [v_x, v_y, v_z]^\top $ 运动的点(注意:由于点是静止的,相机运动导致点在相机坐标系中的运动速度正好相反),其在相机坐标系中的运动速度为:
$$ \dot{\mathbf{P}} = -\mathbf{v} - \boldsymbol{\omega} \times \mathbf{P} $$
写成分量形式:
$$ \begin{aligned} \dot{X} &= -v_x - \omega_y Z + \omega_z Y \\ \dot{Y} &= -v_y - \omega_z X + \omega_x Z \\ \dot{Z} &= -v_z - \omega_x Y + \omega_y X \end{aligned} \tag{3} $$
4. 代入求导公式
将式 (3) 代入式 (1) 和式 (2)。
4.1 推导 $ \dot{x} $
首先,计算 $ \dot{x} $:
$$ \begin{aligned} \dot{x} &= \frac{1}{Z} \left[ \dot{X} - x \dot{Z} \right] \\ &= \frac{1}{Z} \left[ (-v_x - \omega_y Z + \omega_z Y) - x(-v_z - \omega_x Y + \omega_y X) \right] \\ &= \frac{1}{Z} \left[ -v_x - \omega_y Z + \omega_z Y + x v_z + x \omega_x Y - x \omega_y X \right] \end{aligned} $$
将 $ X = xZ $, $ Y = yZ $ 代入:
$$ \begin{aligned} \dot{x} &= \frac{1}{Z} \left[ -v_x - \omega_y Z + \omega_z (yZ) + x v_z + x \omega_x (yZ) - x \omega_y (xZ) \right] \\ &= \frac{1}{Z} \left[ -v_x + x v_z \right] + \left[ -\omega_y + y \omega_z + x y \omega_x - x^2 \omega_y \right] \\ &= -\frac{v_x}{Z} + \frac{x v_z}{Z} + xy \omega_x - (1 + x^2) \omega_y + y \omega_z \end{aligned} \tag{4} $$
4.2 推导 $ \dot{y} $
类似地,计算 $ \dot{y} $:
$$ \begin{aligned} \dot{y} &= \frac{1}{Z} \left[ \dot{Y} - y \dot{Z} \right] \\ &= \frac{1}{Z} \left[ (-v_y - \omega_z X + \omega_x Z) - y(-v_z - \omega_x Y + \omega_y X) \right] \\ &= \frac{1}{Z} \left[ -v_y - \omega_z X + \omega_x Z + y v_z + y \omega_x Y - y \omega_y X \right] \end{aligned} $$
代入 $ X = xZ $, $ Y = yZ $:
$$ \begin{aligned} \dot{y} &= \frac{1}{Z} \left[ -v_y - \omega_z (xZ) + \omega_x Z + y v_z + y \omega_x (yZ) - y \omega_y (xZ) \right] \\ &= \frac{1}{Z} \left[ -v_y + y v_z \right] + \left[ -x \omega_z + \omega_x + y^2 \omega_x - x y \omega_y \right] \\ &= -\frac{v_y}{Z} + \frac{y v_z}{Z} + (1 + y^2) \omega_x - xy \omega_y - x \omega_z \end{aligned} \tag{5} $$
5. 写成矩阵形式
将式 (4) 和式 (5) 按照 $ \mathbf{v}_c = [v_x, v_y, v_z, \omega_x, \omega_y, \omega_z]^\top $ 的顺序整理成矩阵形式:
$$ \begin{bmatrix} \dot{x} \\ \dot{y} \end{bmatrix} = \mathbf{L}_x \begin{bmatrix} v_x \\ v_y \\ v_z \\ \omega_x \\ \omega_y \\ \omega_z \end{bmatrix} $$
其中,交互矩阵 $ \mathbf{L}_x $ 为:
$$ \boxed{ \mathbf{L}_x = \begin{bmatrix} -\frac{1}{Z} & 0 & \frac{x}{Z} & xy & -(1+x^2) & y \\ 0 & -\frac{1}{Z} & \frac{y}{Z} & 1+y^2 & -xy & -x \end{bmatrix} } \tag{6} $$
这就是单个点特征(归一化坐标)的交互矩阵。
6. 交互矩阵的物理意义
$ \mathbf{L}_x $ 的每一列对应于相机速度的一个分量对图像特征速度的贡献。
| 列 | 对应速度分量 | 对 $ \dot{x} $ 的贡献 | 对 $ \dot{y} $ 的贡献 | 物理意义 |
|---|---|---|---|---|
| 1 | $ v_x $ | $ -\dfrac{1}{Z} $ | $ 0 $ | 相机沿 $ X $ 轴平移:点在图像上水平移动,速度与深度 $ Z $ 成反比 |
| 2 | $ v_y $ | $ 0 $ | $ -\dfrac{1}{Z} $ | 相机沿 $ Y $ 轴平移:点在图像上垂直移动,速度与深度 $ Z $ 成反比 |
| 3 | $ v_z $ | $ \dfrac{x}{Z} $ | $ \dfrac{y}{Z} $ | 相机沿 $ Z $ 轴(光轴)平移:引起图像点径向移动(缩放效应) |
| 4 | $ \omega_x $ | $ xy $ | $ 1+y^2 $ | 相机绕 $ X $ 轴旋转(俯仰):引起图像点纵向移动和变形 |
| 5 | $ \omega_y $ | $ -(1+x^2) $ | $ -xy $ | 相机绕 $ Y $ 轴旋转(偏航):引起图像点横向移动和变形 |
| 6 | $ \omega_z $ | $ y $ | $ -x $ | 相机绕 $ Z $ 轴旋转(滚转):引起图像点绕图像中心旋转 |
注意:
- 平移运动(前三列)引起的图像速度依赖于深度 $ Z $。点越近($ Z $ 越小),图像变化越快。
- 旋转运动(后三列)引起的图像速度与深度无关,只与图像点坐标 $ (x, y) $ 有关。
7. 扩展到多个点
对于 $ n $ 个点,将每个点的交互矩阵堆叠起来,形成总交互矩阵:
$$ \mathbf{L} = \begin{bmatrix} \mathbf{L}_{x_1} \\ \mathbf{L}_{x_2} \\ \vdots \\ \mathbf{L}_{x_n} \end{bmatrix} $$
此时,图像特征向量为所有点的坐标拼接而成:
$$ \mathbf{s} = [x_1, y_1, x_2, y_2, \dots, x_n, y_n]^\top $$
特征变化率为:
$$ \dot{\mathbf{s}} = \mathbf{L} \mathbf{v}_c $$
在视觉伺服控制中,通常需要至少 3 个点(6 个特征)才能保证交互矩阵列满秩(6 列),从而唯一求解相机速度。使用少于 3 个点可能导致奇异或欠约束问题。
8. 在视觉伺服控制中的应用
在基于图像的视觉伺服(IBVS)中,控制律通常设计为:
$$ \mathbf{v}_c = -\lambda \widehat{\mathbf{L}}^+ \mathbf{e} $$
其中:
- $ \mathbf{e} = \mathbf{s} - \mathbf{s}^* $ 是当前特征与期望特征之间的误差;
- $ \widehat{\mathbf{L}}^+ $ 是交互矩阵的估计伪逆;
- $ \lambda > 0 $ 是控制增益。
注意:在实际系统中,真实的深度 $ Z $ 往往未知,因此常用估计值 $ \widehat{Z} $ 代替,或者使用其他近似方法(如常数近似、深度独立控制等)。这就是为什么实际控制中常用估计的交互矩阵 $ \widehat{\mathbf{L}} $ 的原因。
9. 关键点总结
- 交互矩阵的推导基于投影几何和刚体运动学。
- 图像特征变化率与相机速度呈线性关系,但该关系依赖于特征点的深度。
- 平移运动引起的图像变化与深度成反比,而旋转运动引起的图像变化与深度无关。
- 实际应用中,深度信息往往不准确,需要使用估计或近似方法。
- 多个点时,将单个点的交互矩阵堆叠即可,但需注意点的数量应足够以保证交互矩阵满秩
近似计算交互矩阵
这一小节主要讲的是:在实际 IBVS 控制里,交互矩阵 $ L_e $ 往往不能精确已知,所以必须构造一个近似的 $ \hat L_e^+ $ 来代替它的伪逆进入控制律。 论文在这里重点比较了 3 种常见近似方法,以及它们各自的效果。
先说为什么要“approximate”。前一节已经推到单点交互矩阵 $ L_x $,其中显式包含深度$ Z $;同时图像特征 (x,y) 的计算也涉及相机内参。所以 $ L_x $ 不能直接精确用于控制,必须对它或它的伪逆做估计。作者还提醒:如果只用 3 个点控制 6 自由度,会出现奇异构型和多解问题,因此实际通常用多于 3 个点。
在这个前提下,论文给了 3 种构造 $ \hat L_e^+ $ 的办法:
第一种是 直接用当前交互矩阵的伪逆
$$ \hat {L_e^+} = L_e^+ $$
前提是当前的 $ L_e $ 已知,也就是每个特征点的当前深度 (Z) 都可得。论文说这类参数在实践中通常需要在控制迭代过程中不断估计。
第二种是 用目标位姿处交互矩阵的伪逆
$$ \hat {L_e^+} = L_{e^*}^+ $$
这里 $ L_{e^*} $ 是误差为零、也就是目标位置处的交互矩阵。它的好处是:$ \hat {L_e^+} $ 变成一个常数矩阵,只需要预先设定每个点的目标深度,视觉伺服过程中就不需要在线估计变化的三维参数。
第三种是 取当前与目标交互矩阵的平均
$$ \hat {L_e^+} = \tfrac12 (L_e + L_{e*})^+ $$
这是文中提到的一个较新的折中方法。因为它包含 $ L_e $ ,所以仍然需要当前深度信息;但作者后面通过仿真说明,这种做法通常能得到更平滑、更好的综合表现。
然后这一节用一个具体例子来比较三种方法:让相机把一个方形目标调整到图像中心。作者故意选了一个离目标位姿较远、尤其旋转偏差很大的初始位姿,因为这正是 IBVS 最容易暴露问题的情况。
仿真结论是:
- 用 $ L_{e^*}^+ $ 时,系统虽然能收敛,但在远离目标时,图像行为、相机速度和三维轨迹都不够理想。
- 用 $ L_e^+ $ 时,图像点轨迹接近直线,但三维运动更差,初始阶段相机速度很大,说明矩阵条件数较高,轨迹离直线也很远。
- 用 $ \tfrac12 (L_e + L_{e^*})^+ $ 时,速度分量没有大振荡,图像空间和三维空间里的轨迹都更平滑,论文明确说它在实践中表现较好。
所以这一节的核心意思可以概括成一句话:
Approximating the Interaction Matrix 这一节在回答“控制律里的 $ \hat {L_e^+} $ 到底怎么选”——作者比较了基于当前矩阵、目标矩阵和二者平均的三种近似,并指出平均法通常是更好的折中。
IBVS的几何解释
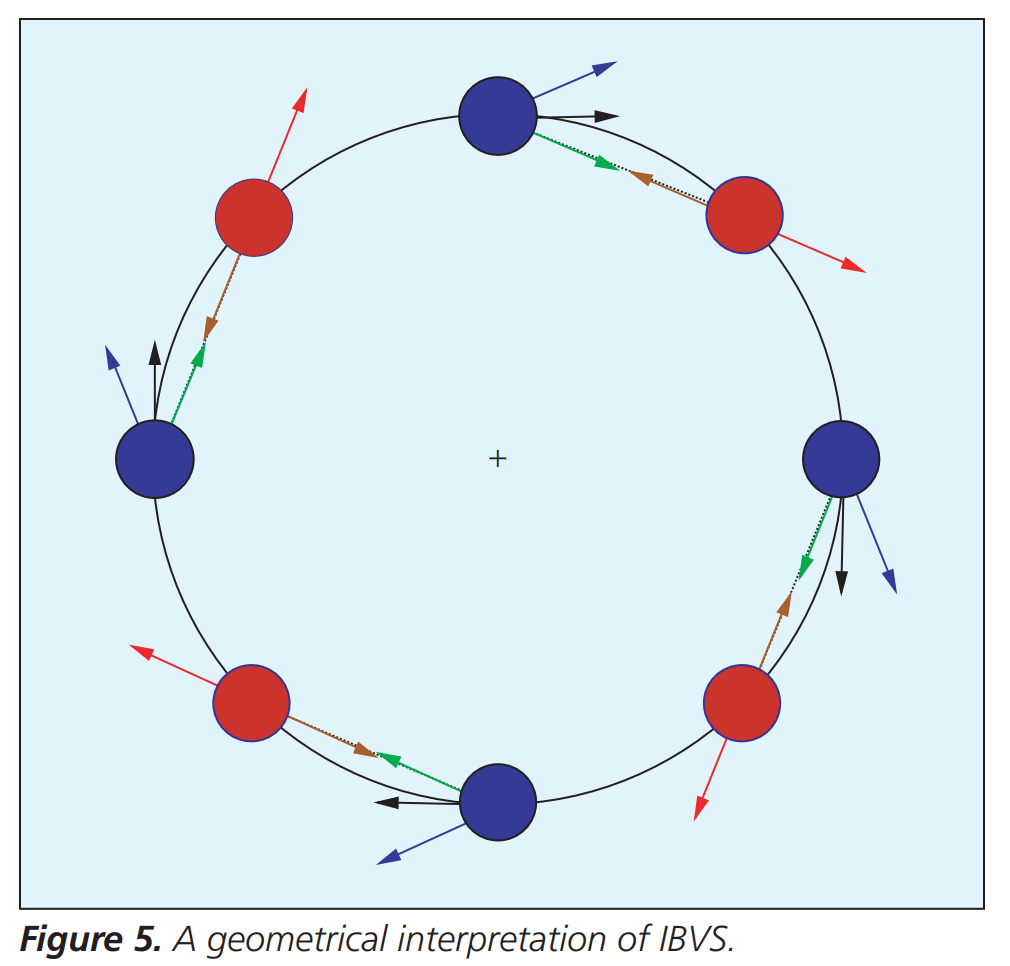
这一节,通过一个具体的几何例子,直观地解释了基于图像的视觉伺服 中不同控制策略所导致的行为差异,特别是解释了为什么IBVS在应对大范围旋转时会产生非直观的相机运动。
该节的核心分析围绕一个特定任务展开:相机需要绕其光轴(Z轴)进行纯旋转,以使一组共面点从初始位姿(蓝色)到达平行于图像平面的期望位姿(红色)。
以下是该节阐述的三种不同控制策略在此场景下的几何行为:
-
使用当前交互矩阵的逆: $ \hat {L_e^+} = L_e^+ $
-
控制目标:此控制律试图使图像误差
e指数衰减。当误差e由点的图像坐标(x, y)构成时,这意味着控制律会驱使图像中的点沿直线从其初始位置(蓝色)运动到期望位置(红色)。 - 实际产生的图像运动:为了产生这种“直线”图像运动(图中绿色路径),相机必须执行一个复合运动:除了绕光轴旋转外,还会伴随一个沿光轴向后的平移运动。这是一个反直觉的现象。
- 原因:这是由于所选图像特征(点的坐标)与相机运动自由度之间存在耦合。具体来说,交互矩阵的第三列(对应沿光轴的平移)和第六列(对应绕光轴的旋转)是耦合的。当旋转误差很大时,这种现象会被放大。在极限情况下(如绕光轴旋转180度),控制律甚至可能完全无法产生旋转运动。
-
控制目标:此控制律试图使图像误差
-
使用期望位置交互矩阵的逆: $ \hat {L_e^+} = L_{e^*}^+ $
- 产生的图像运动:从期望位置(红点)看向初始位置(蓝点),该控制律会产生从红点到蓝点的直线运动(图中棕色路径)。那么,从初始位置到期望位置的实际控制,就是此速度的相反数。因此,在初始位置(蓝点)处,它产生的图像运动方向是图中蓝色箭头所示的方向。
- 对应的相机运动:为了实现这种图像运动,相机的实际运动是绕光轴旋转,但同时伴随一个沿光轴向前的平移。这与第一种情况的方向相反,但同样是“旋转+意外平移”的复合运动。
-
使用当前与期望交互矩阵的平均值的逆:$ \hat {L_e^+} = \tfrac12 (L_e + L_{e*})^+ $
- 行为:这种方法直观上是在前两种极端行为之间取平均。因此,它产生的图像运动是图中黑色箭头所示的路径。在旋转误差较大时,其行为优于前两种;当误差减小时,三种方法的行为会趋于一致。
核心结论:
- 局部与全局行为:IBVS在误差较小(即接近目标位置)时,所有方法都能产生令人满意的行为——图像点沿近似直线的路径运动,相机运动也接近纯旋转。
- 大位移问题:当初始误差很大(特别是存在大旋转)时,由于特征与运动间的非线性耦合,IBVS可能产生不理想、甚至不直观的相机3D运动(如额外的后退或前进)。
- 几何解释的意义:这一节清晰地揭示了IBVS控制器内在的、由特征选择决定的几何特性。它回答了“为什么IBVS有时会产生奇怪的相机路径”这一问题,并为理解其稳定性分析(局部稳定但可能存在局部极小值)提供了直观背景。
使用立体视觉系统的IBVS
“IBVS with a Stereovision System”(基于立体视觉系统的IBVS)这一节的核心,是阐述如何将单目IBVS的框架扩展到双目(立体视觉)系统,并揭示其中的关键变化与约束。
双目系统的视觉特征选择
在双目系统中,如果一个三维点 (P) 同时在左、右相机图像中可见,其视觉特征向量 (s) 可以自然地定义为该点在两个图像平面中坐标的堆叠:
$$ s = \mathbf{x}_s = (\mathbf{x}_l, \mathbf{x}_r) = (x_l, y_l, x_r, y_r) $$
这仍然属于基于图像的方法,因为特征直接来源于图像坐标,未引入三维几何模型。
关键问题:交互矩阵的坐标系统一
直接堆叠特征后,不能简单地将单目的交互矩阵 (L_x) 直接堆叠使用。因为:
$$ \dot{\mathbf{x}}l = L{\mathbf{x}_l} \mathbf{v}_l, \quad \dot{\mathbf{x}}r = L{\mathbf{x}_r} \mathbf{v}_r $$
其中 $ \mathbf{v}_l $ 和 $ \mathbf{v}_r $ 分别是左、右相机坐标系下的空间速度。我们需要一个统一的传感器坐标系(例如与双目系统刚性固联的坐标系)来表达整个系统的运动 $ \mathbf{v}_s $ 。
解决方案:利用空间运动变换矩阵
引入空间运动变换矩阵 (V),用于将速度从一个坐标系变换到另一个坐标系。其形式为:
$$
V = \begin{bmatrix}
R & [\mathbf{t}]_{\times} R \
0 & R
\end{bmatrix}
$$
_
_其中 $ (R, \mathbf{t}) \in SE(3) $ 是从相机坐标系到传感器坐标系的刚体变换(由双目标定得到)。利用此矩阵,双目系统的整体交互矩阵可构造为:
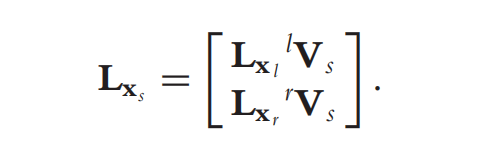
双目也自然引向 PBVS
本节最后还提到一个很自然的延伸:既然双目系统里,一个点在左右图像中都可见,那么可以通过三角化很容易恢复该点的三维坐标。这样一来,如果把这些三维坐标直接放进特征向量 sss 里,那方法就已经不再是纯 IBVS,而更接近 PBVS 了。
PBVS
PBVS(Position-Based Visual Servo)不是直接控制图像误差,而是先从图像中估计相机相对目标的三维位姿,再在三维空间里做闭环控制。
论文一开始就说,PBVS 用的是**相机相对于某个参考坐标系的 pose(位姿)**来定义特征 s。这和 IBVS 最大的区别就在这里:
- IBVS:特征 s直接取图像里的量,比如点的 (x,y)
- PBVS:特征 s 取三维量,比如平移和旋转参数
也就是说,IBVS 里的 s是图像特征,而 PBVS 里的 s 是 3D pose parameters。为了从单张图像恢复这个位姿,必须已知:
- 相机内参
- 被观测目标的 3D 模型
这本质上就是经典的 3D localization / pose estimation 问题。
用到的坐标系
为了描述当前位姿和目标位姿,论文引入了 3 个坐标系:
- 当前相机坐标系 $ F_c $
- 目标相机坐标系 $ F_c^* $
- 附着在物体上的参考坐标系 $ F_o $
并用标准上标记号表示“某个点坐标是相对于哪个坐标系表达的”。例如:
- $ {}^c t_o $:物体坐标系原点相对于当前相机系的坐标
- $ {}^{c^*} t_o $ :物体坐标系原点相对于目标相机系的坐标
此外还定义了旋转矩阵
$$ R={}^{c^∗}R_c $$
表示“当前相机坐标系相对于目标相机坐标系的方向关系” .
如何选择特征
论文把特征统一写成
$$ s=(t,θu) $$
其中:
- $ t $ 是平移向量
- $ \theta u $ 是旋转的轴角表示(angle/axis parameterization)
这里 $ \theta $ 是旋转角,$ u $ 是单位旋转轴,所以 $ \theta u $ 是一个 3 维向量,既表示旋转方向,也表示旋转大小。
接下来论文讨论了 两种不同的 $ t $ 选法,从而得到两种 PBVS 控制器。
第一种 PBVS:用 $ ({}^c t_o,\theta u) $
第一种误差定义
第一种选择把平移定义在物体坐标系原点相对于当前相机系的位置上,于是:
$$ s = ({}^c t_o,\theta u), \qquad s^* = ({}^{c*}t_o, 0) $$
注意这里为什么 $ s^* $ 的第二项旋转为0,因为当到达目标时,当前相机坐标系和目标相机坐标系之间重合,没有旋转
因此误差是
$$ e = ({}^c t_o - {}^{c^*} t_o,\theta u). $$
直观上,这个误差说的是:
- 当前看到的物体原点位置,和目标时应看到的位置差多少
- 当前姿态相对于目标姿态还差多少旋转
第一种交互矩阵怎么写
论文给出对应的交互矩阵
$$ L_e= \begin{bmatrix} -I_3 & [{}^c t_o]_{\times} \\ 0 & L_{\theta u} \end{bmatrix} $$
其中 $ I_3 $ 是三阶单位阵, $ [{}^c t_o]\times $ 是由向量$ {}^c t_o $ 构造的反对称矩阵,$ L{\theta u} $ 是轴角参数的旋转雅可比。
这里最值得注意的是左上和右上的块:
- 左上 $ -I_3 $:说明相机平移会直接影响平移误差
- 右上 $ [{}^c t_o]_\times $ :说明相机旋转也会影响平移误差
所以这种 PBVS 的平移和转动并没有完全解耦。这点后面会直接影响轨迹形状。可以通过集合直觉来理解,相机观察一个固定的物体,当相机原地转动,物体在相机坐标系的(X,Y,Z)也会发生变化。
第一种控制律怎么得到
因为这里特征维数 (k=6),刚好等于相机 6 自由度,所以可以直接用逆矩阵写控制律:
$$ v_c=-\lambda L_e^{-1}e. $$
论文进一步整理后得到显式形式:
$$ v_c = -\lambda\big(({}^{c^*}t_o-{}^c t_o)+[{}^c t_o]_\times \theta u\big) $$
$$ \omega_c = -\lambda \theta u. $$
这个式子很有物理意义:
- 角速度 $ \omega_c $ 只和旋转误差 $ \theta u $ 有关,所以旋转误差被直接指数压缩
- 线速度 $ v_c $ 不仅和位置差有关,还带一个 $ [{}^c t_o]_\times\theta u $ 耦合项,也就是旋转误差会“拖动”平移控制。
第一种 PBVS 的轨迹特性
论文对这种控制器的解释是:
- 旋转运动沿着测地线(geodesic)收敛,且速度指数衰减
- 平移参数也以相同速度衰减
- 因此速度分量衰减得很漂亮,图 7 的速度曲线很规整
- 在图像中,物体参考点(文中取方形中心)走的是直线
- 但相机在三维空间中的轨迹不是直线。
所以这种方法的特征是:
图像里好看,速度衰减也漂亮,但三维相机路径未必最直接。
第二种 PBVS:用 $ ({}^{c^*} t_c,\theta u) $
第二种误差定义
第二种方法换了一种平移参数,取的是:
$$ s=({}^{c^*}t_c,\theta u) $$
此时目标特征就是
$$ s^*=0 $$
因此误差直接等于
$$ e=s $$
这表示:当前相机相对于目标相机的位置和姿态差异,直接作为要被压到零的量。
第二种交互矩阵
对应交互矩阵写成
$$ L_e= \begin{bmatrix} R & 0 \\ 0 & L_{\theta u} \end{bmatrix} $$
这一式最重要的性质是:
平移和旋转完全解耦了。
因为右上角块是 0,所以旋转误差不会再直接混进平移控制里。
第二种控制律
由此直接得到非常干净的控制律:
$$ v_c = -\lambda R{}^{c^*}t_c $$
$$ \omega_c = -\lambda \theta u. $$
你可以把它理解成:
- 平移控制就是把当前相机往目标相机位置“直推”过去
- 转动控制就是按轴角误差直接纠正姿态
第二种 PBVS 的轨迹特性
论文说这种情况下,如果位姿估计完全准确,那么:
- 相机的三维轨迹是纯直线
- 但图像轨迹比前一种更差
- 有些构型下,目标点甚至会跑出视野。
这说明它的特点恰好和第一种互补:
三维空间轨迹最自然,但图像空间行为不一定好。
这两种 PBVS 的本质区别
为什么只换一个平移定义,行为差这么多
根本原因在于误差参数化不同,导致交互矩阵结构不同。
第一种:
$$ L_e= \begin{bmatrix} -I_3 & [{}^c t_o]_\times \\ 0 & L_{\theta u} \end{bmatrix} $$
平移和旋转耦合,因此控制更“视觉导向”,图像轨迹较自然,但三维相机路径不是最短。
第二种:
$$ L_e= \begin{bmatrix} R & 0 \\ 0 & L_{\theta u} \end{bmatrix} $$
平移和旋转解耦,因此三维路径更理想,但图像运动可能不理想,甚至丢失目标。
所以论文其实在告诉你:
PBVS 并不是只有一种写法,误差怎么参数化,会直接决定控制器的几何行为。
这一节和 IBVS 的关系
论文为什么把 PBVS 放在这里讲
因为前文的统一框架是
$$ e=s-s^*, \qquad \dot e=L_e v_c, \qquad v_c=-\lambda \hat L_e+ e. $$
IBVS 和 PBVS 的核心差异只在于 $ s $** 选什么**:
- IBVS:$ s $ 是图像里的 2D 特征
- PBVS:$ s $ 是三维位姿参数
PBVS 这里其实就是把同样的控制框架搬到了位姿空间。因此它能更直接地“指定相机在 3D 空间该怎么走”。
PBVS 的优势
从这一节和后面的总结能看出,PBVS 的优点是:
- 控制目标定义在三维空间,物理意义清楚
- 可以直接设计更自然的笛卡尔轨迹
- 理论稳定性看起来更漂亮;后文还指出,在理想位姿完全准确时,可得到全局渐近稳定结论。
PBVS 的代价
但它的代价也很明显:
- 必须先做 pose estimation
- 依赖相机内参与物体 3D 模型
- 对位姿估计误差更敏感
- 图像空间行为不一定好,可能出现目标离开视野的问题
论文最后总结得很直接:
在 PBVS 中,视觉传感器其实被当成 3D 传感器 在用;如果单目位姿估计有偏差,哪怕图像测量误差很小,也可能导致控制精度和稳定性明显变差。
总结
IBVS稳定性
- ❌ 不保证全局收敛
⚠️ 可能陷入局部极小⚠️ 可能遇到奇异性- ✔ 在目标附近通常稳定
- ✔ 实际中“收敛域往往还挺大”(经验结论)
PBVS稳定性
- ✔ 理论上全局稳定(理想条件)
- ❌ 实际依赖位姿估计精度
- ❌ 对噪声、标定误差非常敏感
⚠️ 可能“看起来对了但其实错了”
IBVS:稳定性好在“现实鲁棒性”,但理论上只有局部稳定;
PBVS:理论上全局稳定,但现实中依赖位姿估计,容易失真甚至不稳定。